Blog Posts
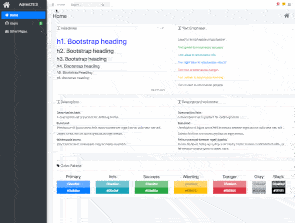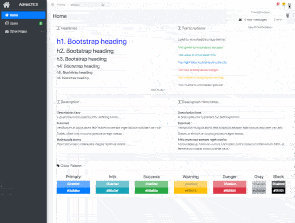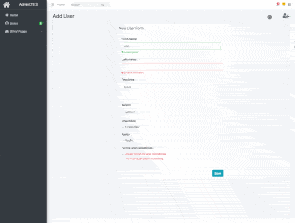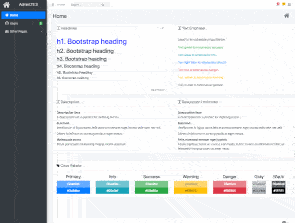
Let’s set up a boilerplate project using Next.js, Bootstrap & AdminLTE.
You can use this as a skeleton to build your projects from.
We’ll integrate the following libraries:
- Next.js
- React
- AdminLTE
- SASS
Let’s build a simple skeleton react native app with redux and some other necessities.
You can use this as a template to build your own app from.
- React / Redux
- React Native Vector Icons
- React Native Navigation
- React Native Splash Screen

When learning a new programming language, you normally write a “Hello World!” application.
The hello world equivalent in machine learning is the MNIST handwriting recognition application.
Let’s follow through the Tensorflow beginner tutorial to gain a better understanding of deep learning.
Let’s build a simple classification model using tensorflow for house prices.
I’ve started working through Siraj Raval’s youtube tutorials to teach myself deep learning. I’ve become aware there’s still a long way to go, but I’m very excited about this.
This is a post of the notes I take along the way.
- Data parsing and processing using data frames
- Splitting our data into a training and testing set
- Simple linear regression modal to find our line of best fit
- Slope formula - \(y = mx + b\)
- Hyperparameters
- Sum of squared errors
- Local minima
- Gradient descent
- Partial derivative
- The McCulloch-Pitts Model of Neuron (1943)
- The Perceptron
- Forward propagation
- Backpropagate to update weights
I wanted to tether my rooted S5 android to my ASUS N66U router so I could use my mobile data connection through my router over a VPN.
Getting this working with a VPN for both USB and wifi was a little more tricky than I thought, but I found the following two solutions in the end.
I use Amazon S3 to host my simpler static websites, it’s simple, cheap and removes all the hassle from administering a web server.
I had to add some redirect rules to redirect some of my posts from my old url format to my new one. This is how I did it.
This was a template I created with troposphere and launches an nginx and node.js (with PM2) stack on AWS via cloudformation.
It takes no parameters, but depends on the following Exports from another cloudformation stack.
Require Exports
- ElasticIP
- A export named ElasticIP (Domain Stack)
- VPC
- A export named VPC (VPC Stack) to add security groups
- Subnet1
- A export named Subnet1 (VPC Stack) to add our instance into
This was a template I created with troposphere and launches a PHP stack on AWS via cloudformation.
It takes no parameters but depends on the following Exports from another cloudformation stack.
Require Exports
- ElasticIP
- A export named ElasticIP (Domain Stack)
- VPC
- A export named VPC (VPC Stack) to add security groups
- Subnet1
- A export named Subnet1 (VPC Stack) to add our instance into
This was a template I created with troposphere and launches a VPC stack on AWS via cloudformation.
It consists of a VPC, subnets, route tables and an internet gateway.
Outputs
- VPC (Export)
- A VPC named VPC
- Subnet1 (Export)
- A subnet named Subnet1
- Subnet2 (Export)
- A subnet named Subnet2
This was a template I created with troposphere and launches a domain stack on AWS via cloudformation.
You specify the ZoneRecordName and select an existing HostedZoneId via the parameters, and we create a new domain type A record in Route53.
Parameters
- ZoneRecordName
- The record name to be created e.g: anil.io, dev.domain.com
- HostedZoneId
- The hosted zone id from Route53 for this domain. e.g: Z5JQDH44CCPRO
Outputs
- ElasticIP (Export)
- The elastic ip that was created and attached to ZoneRecordName
- DomainName
- String value of the ZoneRecordName
A guide on setting up node.js on an EC2 server with forever to run a HTTP server.
We also setup forever to run our script when the instance boots.
Using FOSUserBundle you may want to redirect the user to the homepage when they visit the login page and already logged in, this isn’t provided by default in the bundle, but it’s very easy to implement.
It involves overriding the FOSUserBundle with your own child bundle and then adding your own custom implementation of the loginAction which redirects the user as required. Let’s have a look at how to do this.
I’ve recently switched to using a static blog generator for my blog. I have the domain name anil.io, I wanted all the emails received to any addresses under this domain to be forwarded to another email address.
I wanted to host this blog on AWS S3 as a static web site with HTTPS and turbocharge it through amazon’s CloudFront CDN. I needed to use AWS Certificate Manager to verify my domain by sending a verification email and then proceed to link to certificate to CloudFront.
This is a tutorial on how to setup amazon web services SES service to receive emails using S3 and to forward them on to another target using an AWS Lambda script with Node.js.
Selenium is an awesome tool to automate the testing of your application, although, there are several better performing headless solutions available today for testing (Phantom.js, Zombie.js). Selenium can still be extremely useful to load a web page, perform some actions like a search and extract data from it.
Here are 2 answers I posted on StackOverflow.com demonstrating the basic concept, let’s have a look and get up and running with Selenium.
How to use Selenium with PHP? Disable images in Selenium PythonI learned an awesome YAML feature today, the ability to use variables in YAML files.
I’m not talking about application variables, but blocks of re-usable YAML which you can reference later on in your file.
Searching online, you won’t find much information on this, but it is in the official YAML specification.
Let’s have a look at this amazing YAML (relatively unknown) feature!

A guide on installing AWS tools on Tomato Shibby to roll your own dynamic DNS service.
Tomato Shibby is a custom firmware which can be flashed on to routers to provide many aftermarket features and also access to root. One example is that you can connect an external HDD to the router and use it as a media server.
This is a short guide to get up and running with Entware, Python and awscli tools. We’ll install a script which will update the DNS on AWS Route 53 when the IP of the router changes.
I had some free time today and somehow ended up reading the HTTP spec, I found something that made me chuckle.
Did u know there is a HTTP status code "418 - I'm a teapot" - You programmers crack me up! - https://t.co/6iNSPAA9um
— Anil (@anil_io) June 14, 2015
A guide on how to install Apache Nutch v2.3 with Hbase as data storage and search indexing via Solr 5.2.1.
Apache Nutch is an open source extensible web crawler. It allows us to crawl a page, extract all the out-links on that page, then on further crawls crawl them pages. It also handles the frequency of the calls and many other aspects which could be cumbersome to setup.
Let’s have a look at setting up Apache Nutch with Hbase.
A guide on how to install Apache Nutch v2.3 using MySQL as database storage and search indexing via Solr 5.2.1.
Apache Nutch is an open source extensible web crawler. It allows us to crawl a page, extract all the out-links on that page, then on further crawls crawl them pages. It also handles the frequency of the calls and many other aspects which could be cumbersome to setup.
Let’s have a look at setting up Apache Nutch with MySQL.
This is a guide for setting up and maintaining a dreambox satellite set top box.
A dreambox runs a small subset of Linux called busybox. Unlike a full blown linux installation, busybox is built for embedded devices and so has a much slimmer set of pre-installed tools.
When managing software on a busybox embedded system you have to be careful not to use up all the internal flash storage memory. In this post, we manage to install all our required packages, and still keep several megabytes free.
PHP Quality Assurance tools are a must for any project, they can help in the analysis and optimization of your code by testing your code autonomously, finding duplicate code across your code base and giving you useful metrics towards your project goals.
In this post, we’ll discuss a few of the commonly used tools in PHP, and the very basics of how they are used. You’d usually use them in a continuous integration environment like Jenkins, but can also be run locally through your IDE whilst developing for a more real time update.
Think of phing as bash scripting with xml. It allows us to do things like:
- Make a directory
- Give it x permissions
- Copy some files into it
Instead of us using bash to script all these, we can use phing. Phing allows us to script all of these tasks using xml. Phing is based off a more popular tool (which if i’m honest I prefer) called Apache Ant.
In this post, we will cover the installation, setup and basic usage of Jenkins.
If you’ve never heard of Jenkins before, Jenkins is a continuous integration tool which automates the building of your application, it can be set up to unit test your code, check for mess detection & coding standards as well as many other things after each commit or before a release build.
I’m a huge fan of unit testing, I love being able to automate the testing of your code as well as using tools like mess detection, phplint & phpcs to write cleaner, consistent testable code.
Let’s have a look at the different ways of installing packages in PHP. We’ll cover Composer, Phar archives and PEAR packages.
Symfony’s Console component and the commands provided by Symfony framework are one of my favourite things about Symfony, it can help to quickly bootstrap a new project or perform tasks whilst maintaining an existing one.
This was a script I came across on Github to enable Symfony console auto complete for all projects without adding any additional code to your projects.
Say I started typing app/console cacTAB, this script would allow me to auto complete the cache command or view the available commands. This also works for your own console commands on a per project basis.